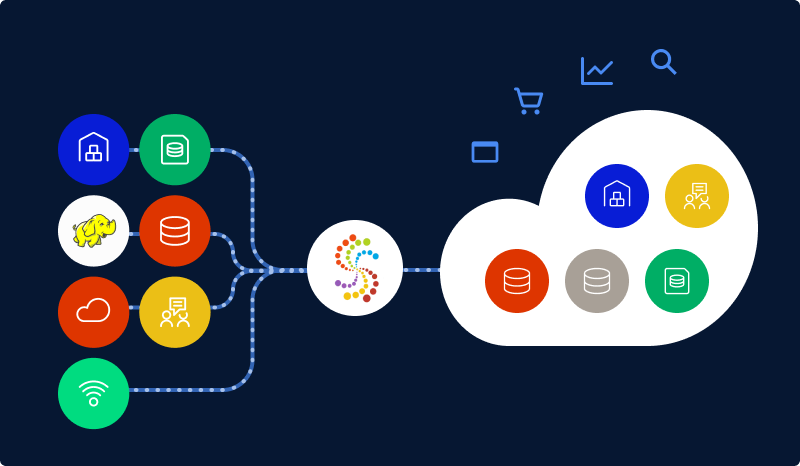
In recent years, the amount of data generated by brands has been increasing rapidly. This can be possible due to affordable storage and faster internet connectivity. In this article, we’ll discuss data ingestion, its benefits, and some challenges associated with serverless data ingestion.
Let’s get started!
Data Ingestion
Ingestion is the process of bringing data into the processing system. Data can be ingested in real-time or in batches using an ingestion framework, which moves data from it’s origin to a system where it can be stored and analyzed. When ingesting data in batches using the ingestion pipeline, the information is ingested periodically in chunks. On the other hand, real-time ingestion involves ingesting the data immediately upon its arrival.
Popular Serverless Data Ingestion Tools and Frameworks
1. Airbyte
It’s an open-source data ingestion tool that focuses on extracting and loading data. The tool is designed to simplify the setup of data pipelines and maintain data flow through the pipeline. It offers over 120 data connectors, including Google Analytics, Salesforce, and local files, and provides access to both raw and normalized data.
2. Amazon Kinesis
It is a cloud-based service for data ingestion and processing. This tool is capable of ingesting and analyzing large distributed data streams from thousands of different sources.
3. Hevo
This is a fully automated and no-code data pipeline platform, which supports 150+ ready-to-use integrations across Databases, SaaS apps, cloud storage, SDKs, and streaming services.
4. Apache Storm
It is a distributed real-time data ingestion and processing framework designed to handle large volumes of data. The framework provides a simple programming model that enables developers to quickly build apps capable of processing data streams in real-time. Apache Storm is commonly used for low-latency data processing, such as real-time analytics and event processing.
5. Apache Flume
Apache Flume is a distributed, reliable and available service for collecting and moving large amounts of log data. Its flexible and straightforward architecture is based on streaming data flows, making it a robust tool with reliability mechanisms, failovers, and recovery mechanisms. Apache Flume also uses a simple and extensible big data security model, enabling an online analytic application and ingestion process flow. The different functions of Apache Flume include:
- Stream data: This function enables the ingestion of streaming information from multiple sources into Hadoop for storage and analysis.
- Scale horizontally: This function includes the addition of new ingestion streams and scaling up to handle extra volume as needed.
6. Apache Nifi
Apache Nifi is a powerful and reliable Ingestion tool that provides an easy-to-use system for processing and distributing information. It supports robust and scalable directed graphs of routing, transformation, and system mediation logic. The functions of Apache Nifi include:
- Information flow tracking: It can track information flow from start to end.
- Secure experience: The experience between design, control, feedback, and monitoring is strong because of SSL, HTTPs, and encrypted content.
7. Elastic Logstash
Elastic Logstash is an open-source ingestion tool that can ingest information from different sources, transform it, and send it to your “stash”, i.e., Elasticsearch. The tool include multiple AWS services in a continuous, streaming fashion, and can ingest data of all shapes, sizes, and sources, including logs, metrics, and web apps.
Benefits of Serverless Data Ingestion
Using a serverless backend offers numerous benefits, including custom runtime billing, cost effective scaling, elimination of the need for glue code, and a shift to an on-demand billing model for orchestration.
In addition, a serverless data ingestion provides important benefits such as:
- It loads data into the destination system in a way that is scalable and efficient.
- It provides tools and interfaces for monitoring and managing the data ingestion process.
- It transforms and cleans the data to make it suitable for the destination system.
- It can extract data from multiple sources, such as files, database, and streaming data.
Challenges of Serverless Data Ingestion
As the number of IoT devices increases, the variety of information and volume of sources also expand rapidly. Ingesting data at a reasonable speed and efficiently processing it is a major challenge. This is especially true when dealing with different sources in different formats. Here are some of the challenges that can be experienced during serverless data ingestion:
- Incorrect ingestion can result in unreliable connectivity, disrupt communication, and cause information loss.
- Semantic change over time when the same data powers new cases.
- Modern source tools and consuming apps evolve rapidly during data ingestion.
- Detecting and capturing changed data is difficult due to the semi-structured or unstructured nature of data.
Best Practices of Data Ingestion
It’s recommended to use the right tools and principles in order to complete the process of data ingestion:
Network bandwidth: The data pipeline should coexist with business traffic. Scaling it is one of the biggest pipeline challenges due to changes in traffic. Thus, ingestion tools are necessary for bandwidth throttling and compression capabilities.
Streaming data: Depending on specific data ingestion requirements, the tools should be capable of supporting data processing in batch, streams or real-time. This enables greater flexibility in handling different types of data.
Choose the right format: The ingestion tools should provide a serialization format. The information should come in the variable format so that converting them into a single format will provide an easy view to understand or relate the data.
High accuracy: One of the greatest challenges is to build trust with consumers and make sure that the data is auditable. So, one of the best practices to implement is never discard inputs or intermediate forms when altering data in the ingestion process flow.
Manage data connections: Ensure that connections are both dependable and secure, and capable of handling expected volume and velocity of incoming data. Moreover, have a plan in mind to manage data connections when unexpected spikes in data volume occur.
Maintain scalability: As data volumes and sources can vary greatly, it is important to have a scalable data ingestion pipeline that can handle the fluctuations in data volume and velocity. This ensures that the pipeline can accommodate future growth and changes in data sources.
Latency: The more fresh your information is, the agile your company’s decision-making process will be. In actuality, extracting data from APIs and databases in real-time can be difficult. Therefore, the target information sources are used, such as Redshift, Amazon Athena for receiving information in chunks.
Business decisions: The critical analysis is possible when combining information from multiple sources. It is important to have a single image of all the data coming in for making business decisions.
Other recommendations
Data volume: Backing up aggregate information can be a useful practice, but it depends on the specific needs and goals of the data ingestion process. So, while managing and storing large volumes of data, consider data partitioning, compression, and archiving.
Capacity and reliability: The system should be able to scale up or down based on the volume of data being ingested and should also be fault-tolerant to ensure that data is not lost in case of any failures or errors.
Data quality: Ensure that the consuming apps work with correct, consistent, and trustworthy information to apply data approach’s best practices.
Conclusion
In the era of Internet of Things (IoT), a vast amount of information is available, and thus there is a need for an efficient analytics system and excellent management practices. This can be achieved through the use of data ingestion, pipelines, tools, best practices, and modern batch processing to quantify and trach each aspect effectively.
If you have any thoughts on data ingestion, comment below. We’d like to hear from you!
Author bio:
Hardik Shah is a Tech Consultant at Simform, a premier digital product engineering firm. He leads solution architecture initiatives for large scale mobility programs. He has lend his expertise in platforms, solutions, governance, and standardization to oversee multiple successful enterprise projects. Connect with him to discuss the best practices of digital product engineering & cloud transformation.








{kind=link}